Bardzo często zachodzi konieczność zmiany nazwy kolumny zwracanej poprzez zapytanie select. Domyślną wartością jest nazwa pola w tabeli. Efekt zmiany nazwy kolumny można uzyskać w następujący sposób:
Wykorzystując operator as:
select nazwa_kolumny as nowa_nazwa from tabela
Lub w uproszczony sposób – pomijając operator as:
select nazwa_kolumny nowa_nazwa from tabela
Uwaga: Zwracane nazwy kolumn poprzez select powinny być unikatowe. Nie jest to wymagane, ale czasem znacznie upraszcza szukanie błędów.
Przykład:
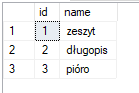
Załóżmy, że mamy następującą tabelę countries:
Zawartość tabeli: countries
Aby zmienić nazwę kolumny name na text użyjmy jednej z następujących kwerend:
Bardzo często zachodzi potrzeba zgrupowania danych oraz wyciągnięcia z nich jakiś informacji, np ilości rekordów, wartości średniej, minimalnej itp. Podczas pisania kwerendy select można zlecić silnikowi bazy zgrupowania danych. Służy do tego operator group by. Aby wyciągnąć informacje z zgrupowanych danych, trzeba użyć funkcji agregujących. Podstawowe funkcje agregujące opisałem tutaj.
Podstawowa forma użycia operatora group by:
select pola from tabela group by pola_grupowania
Pola_grupowania służą do zdefiniowania, według których silnik bazy danych ma przeprowadzić grupowanie danych. Te pola mogą zostać zwrócone bezpośrednio przez kwerendę. Inne pola, po których grupowanie nie jest przeprowadzane, muszą być zwrócone poprzez funkcje agregujące.
Having:
Warunek where jest stosowany przez silnik bazy danych do poszczególnych rekordów. Niektóre sytuacje wymagają, aby wykonać operacje na zbiorach danych poprzez funkcje agregujące, wyciągając informacje analityczne dla jakiegoś przypadku.
Klauzura having pozwala wykonać warunek na zbiorach z użyciem funkcji agregujących, jest wykorzystywana razem z group by.
Zasada użycia having:
select pola from tabela group by pola_grupowania having warunek
Warunek zostanie zastosowany do pogrupowanych zbiorów danych.
Przykłady:
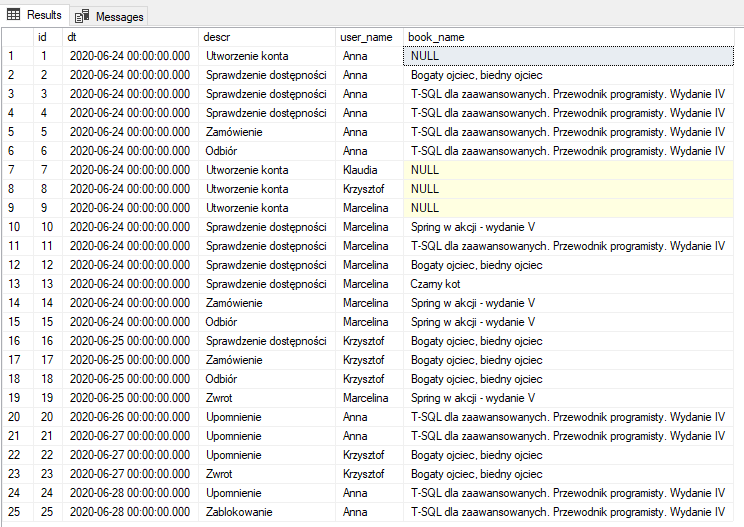
W przykładnie dla ułatwienia będę korzystał z widoku vuser_history_data. Zakładam zwracanie następujących danych:
Dane wykorzystywane w przykładzie: widok vuser_history_data
Group by:
Przykład 1:
Zgrupujmy dane po user_name i wyświetlmy ilość rekordów, możemy do tego wykorzystać następujący kod:
select user_name, count(dt) as count_dt, count(book_name) as count_book_name, count(distinct book_name) as unique_book_name
from vuser_history_data
group by user_name
Dla danego przykładu zostaną zwrócone następujące dane:
Wynik kwerendy: select user_name, count(dt) as count_dt, count(book_name) as count_book_name, count(distinct book_name) as unique_book_name from vuser_history_data group by user_name
Otrzymane wyniki wymagają następującego komentarza:
Dla danych zgrupowanych po user_name count(dt) as count_dt zliczyło wszystkie wartości dt. Count(book_name) as count_book_name zwróciło inne wartości niż dla dt, ponieważ niektóre pozycje mają wartość null i zostały pominięte. Count(distinct book_name) as unique_book_name przed zliczeniem wyeliminował duplikaty.
Przykład 2:
Sprawdźmy osoby, które dostały upomnienia. Uzyskajmy informacje: kto, datę pierwszego upomnienia oraz ilość upomnień:
select user_name, min(dt) as dt, count(dt) as count from vuser_history_data
where descr = 'Upomnienie'
group by user_name
Uzyskamy następujące wyniki:
Wynik powyższego zapytania: select user_name, min(dt) as dt, count(dt) as count from vuser_history_data where descr = 'Upomnienie’ group by user_name
Przykład 3:
Grupować możemy po wielu kolumnach:
select user_name, descr
from vuser_history_data
group by user_name, descr
Otrzymamy wyniki:
Rezultat zapytania: select user_name, descr from vuser_history_data group by user_name, descr
Ciekawostka:
Można zliczać po kolumnie, po której grupujemy:
select user_name, count(user_name)
from vuser_history_data
group by user_name
Wynik działania kwerendy: select user_name, count(user_name) from vuser_history_data group by user_name
Ponieważ cały czas mamy wszystkie rekordy zwracane przez widok, ale silnik bazy danych dokonał ich podzielenia według user_name.
Having:
Przykład 1:
Do kodu z przykładu 2 z użycia group by dodajmy klauzurę having, której zadaniem będzie zwrócenie użytkowników, których minimalna data będzie większa lub równa 2020-06-27:
select user_name, min(dt) as dt, count(dt) as count from vuser_history_data
where descr = 'Upomnienie'
group by user_name
having min(dt) >= '20200627'
Otrzymamy:
Wyniki zwrócone poprzez powyższe zapytanie.
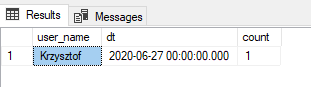
Przykład 2:
Jeśli potrzebujemy wyświetlić rekordy, dla których ostatnia data jest większa lub równa 2020-06-27 to możemy użyć następującego kodu:
select user_name, max(dt) as dt, count(dt) as count from vuser_history_data
group by user_name
having max(dt) >= '20200627'
Jako rezultat zobaczymy:
Rezultat: select user_name, max(dt) as dt, count(dt) as count from vuser_history_data group by user_name having max(dt) >= '20200627′
Podsumowanie:
Jednym z głównych elementów do których są wykorzystywane gropy by oraz having są raporty oraz wszelkiego rodzaju dane analityczne. Służą do uzyskania danych, które da się pogrupować w zbiory.
Aby wyciągnąć konkretne informacje należy wykorzystać funkcje agregujące. Pozwalają na wykonanie obliczeń typu min, max, oraz innych.
Having pełni rolę operacji where na zgrupowanych danych. Jest wykonywany po pogrupowaniu danych. Operator where działa dla poszczególnych rekordów, a having dla zbiorów.
W języku SQL możemy wyróżnić następujące operatory porównania:
operator równe =
operator mniejsze niż <
operator większe niż >
operator różne <>
operator większe lub równe >=
operator mniejsze lub równe <=
Wykorzystywane zazwyczaj w warunkach where, zwracają wartości logiczne true, false lub wartość null.
Wartość true jest zwracana, gdy warunek jest spełniony, wartość false w przeciwnym wypadku – gdy warunek jest niespełniony. Wartość null jest zwracana w przypadku, jeśli jednym z argumentów operatora jest wartość null.
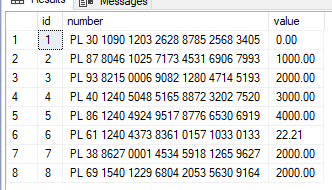
Przykłady użycia:
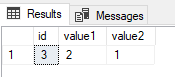
Zakładam następujące dane testowe:
Zawartość tabeli data_values
Operator równe =
Kod który pozwala wyświetlić rekordy, których value1 jest równe value2 to:
select * from data_values where value1 = value2
Rezultatem powyższego zapytania jest:
Wynik kwerendy: select * from data_values where value1 = value2
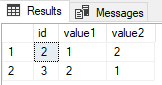
Operator mniejsze niż <
Aby wyświetlić rekordy, dla których spełniony jest warunek value1 < value2 wystarczy użyć kodu:
select * from data_values where value1 < value2
Uzyskamy:
Wynik zapytania: select * from data_values where value1 < value2
Operator większe niż >
W celu wyświetlenia rekordów, dla których value1 jest większe niż value2:
select * from data_values where value1 > value2
Otrzymamy:
Rezultat: select * from data_values where value1 > value2
Operator różne <>
Działanie operatora różne można zobaczyć wykorzystując poniższy kod:
select * from data_values where value1 <> value2
Rezultatem dla powyższych danych jest:
Wynik zapytania: select * from data_values where value1 <> value2
Operator większe lub równe >=
Aby zobaczyć działanie operatora większe lub równe użyjmy kodu:
select * from data_values where value1 >= value2
Uzyskamy:
Rezultat kwerendy: select * from data_values where value1 >= value2
Operator mniejsze lub równe <=
Działanie operatora mniejsze lub równe można sprawdzić poprzez kod:
select * from data_values where value1 <= value2
Co da następujący wynik:
Wynik dla powyższego zapytania: select * from data_values where value1 <= value2
Zamiast tworzyć bardzo rozbudowane warunki where w zapytaniu select, można podzielić kwerendę na kilka mniejszych, łatwiejszych w utrzymaniu zapytań SQL i połączyć je za pomocą operatora union lub union all. Wartości odczytane po operatorze union są doklejane do poprzedniego wyniku zapytania select.
select nazwy_kolumn from tabela1
union lub union all
select nazwy_kolumn from tabela2
Uwaga: W przypadku, jeśli wartości drugiego zapytania nie będą mogły być doklejone do pierwszego, to zostanie zwrócony błąd. Taka sytuacja może wystąpić w skutek niegodności ilości kolumn oraz ich typów.
Różnica między union oraz union all polega na tym, że duplikaty rekordów zostaną usunięte przed zwróceniem wartości. Union all spowoduje pozostawianie zdublowanych rekordów. Nazwy zwracanych rekordów zostaną przepisane z pierwszego wyrażenia select.
Można napisać kwerendę z kilkoma użyciami union. W praktyce taka sytuacja świadczy o słabym zrozumieniu danych przechowywanych w bazie i lepszym pomysłem będzie poprawienie tego. Pozbycie się operatorów union powinno w odczuwalny sposób wpłynąć na czas odczytu danych z bazy danych.
Uwaga: Nie zalecam mieszania union oraz union all w jednej kwerendzie. Można uzyskać ciekawe rezultaty oraz błędy logiczne. Użycie union jako ostatniego spowoduje usunięcie duplikatów z poprzednich rezultatów. Dokładnie tak, jak użycie operatora distinct.
Uwaga: Zalecam stosować union all wszędzie tam, gdzie nie występują duplikaty. Kod SQL będzie wykonywany szybciej, ponieważ nie jest wykonywany krok usuwania duplikatów,
Przykłady:
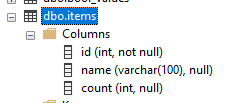
Dla danych w tabeli items:
Zawartość tabeli items
Łączenie różnych wartości:
Możemy dodać rekordy zwracane poprzez zapytanie select, nie modyfikując tabeli items. używając kodu:
select * from items
union all
select 5, 'kubek'
Wynikiem działania kodu będzie zwrócona zawartość tabeli items wraz z nową wartością:
Wynik działania kodu
Kod z użyciem union zwróci dokładnie takie same rezultaty.
Porównanie działania union oraz union all:
Połączmy dokładnie dwa takie same rezultaty, czyli kwerendy select do tej samej tabeli.
Union all:
select * from items
union all
select * from items
Zwróci rezultaty:
Rezultat działania union all
Union:
select * from items
union
select * from items
Zwróci rezultatu:
Rezultat działania union
Kod drugiego zapytania wyeliminował duplikaty rekordów.
Łączenie różnych danych:
Operator union można wykorzystać także do łączenia różnych wyników. Jedynym warunkiem jest to, że ostatecznie zwracane typy muszą być zgodne z wynikiem pierwszego zapytania:
Dodatkowo użyjmy tabelki users:
Zawartość tabeli users
Możemy wykonać następujący kod:
select id, name from items
union
select id, cast(dt_create as varchar) from users
Jawne określenie typów w polach tabeli powoduje, że niosą informację. Nawet wartości powszechnie uznane za puste. Pusty ciąg znaków to ciąg o długości 0. Wartość liczbowa niczego to zero. Czasem zachodzi konieczność zapisania rekordu, który nie będzie miał konkretnej wartości w danym polu. Będzie wymagana wartość nieokreślona – null. Ma szczególne zastosowanie dla kluczy obcych. Relacje oparte o klucze obce wymagają, aby wartość z jednej tabeli była obecna w drugiej. Wartość null pozwala na dodanie wpisu, dla którego taka relacja nie obowiązuje.
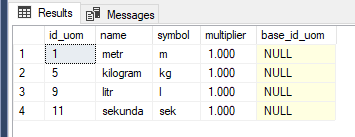
Tworzenie tabeli dopuszczającej wartości null:
Tworząc nową tabelę, dokonuje się wyboru: czy i które pola będą dopuszczać wartości null. Jeśli podczas tworzenia tabeli nie zostanie to jawnie zadeklarowane, to zazwyczaj wartość null będzie dopuszczana.
Jeśli pole ma dopuszczać wartość null wystarczy dodać do definicji pola null w kwerendzie create table. Aby pole wykluczało wartości null wystarczy dodać not null.
Używając alter table można zmienić dopuszczalność wartości nieokreślonych.
Przykład:
Dla tabeli:
create table uoms(
id_uom int identity primary key,
name varchar(100) not null,
symbol varchar(5) not null,
multiplier numeric(10,3) not null,
base_id_uom int null
constraint FK_base_id_uom foreign key (base_id_uom) references uoms(id_uom)
)
Podczas tworzenia tabeli jawnie określono, aby tylko pole base_id_uom dopuszczało wartość null. Jest równocześnie kluczem obcym wskazującym na inne rekordy id_uom w tej tabeli.
Zobaczymy w polu base_id_uom wartość null dla rekordu id_uom = 1
Wartość null w tabeli.
W przypadku, gdy do tabeli spróbujemy dodać wartość null tam, gdzie jest to niedozwolone dostaniemy błąd. Np. Dla Ms SQL Serwer będzie on wyglądał następująco:
Cannot insert the value NULL into column X, table Y column does not allow nulls. INSERT fails.
Praca z wartością null:
Aby sprawdzić pole w rekordzie, czy zawiera wartość null wystarczy użyć konstrukcji is null, is not null. Innym sposobem jest użycie funkcji IsNull(), która w braku wartości zwraca wartość podaną jako drugi parametr lub jej odpowiedników.
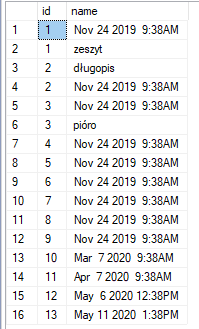
Przykład:
Dla zawartości tabeli uoms:
Zawartość tabeli uoms
Możemy sprawdzić, które wartości mają null w polu base_id_uom używając kodu:
select * from uoms where base_id_uom is null
Otrzymamy wyniki:
Wynik zapytania: select * from uoms where base_id_uom is null
Odwrotny wynik można uzyskać poniższym zapytaniem select:
select * from uoms where base_id_uom is not null
Rezultat:
Rezultat zapytania: select * from uoms where base_id_uom is not null
Taki sam rezultat uzyskamy używając:
select * from uoms where base_id_uom <> ''
Ponieważ operator porównania dla wartości null zwraca wartość null. Dla innych wartości zostanie zwrócona wartość logiczna porównania.
Wywołania funkcji jest następująca: nazwa_funkcji(argumenty).
Count():
Funkcja zwraca zliczoną wartość podaną jako argument. Możemy podać nazwę kolumny po której chcemy zliczać lub użyć znaku *, gdy nie jest to istotne. W takim wypadku silnik bazy danych wybierze najlepszą opcję.
Przykłady:
W przykładzie będziemy używać następujących danych w tabeli accounts:
Zawartość tabeli accounts
Count:
Dla kodu:
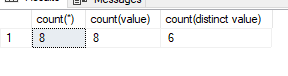
select count(*) as 'count(*)', count(value) as 'count(value)', count(distinct value) as 'count(distinct value)' from accounts
Otrzymamy wyniki:
Rezultat: select count() as 'count()’, count(value) as 'count(value)’, count(distinct value) as 'count(distinct value)’ from accounts
Wartość count(distinct value) zwróciła 6, ponieważ 3 konta mają taką samą wartość, słowo kluczowe distinct eliminuje duplikaty.
Min(), max(), sum(), avg():
Dla przykładu w tabeli accounts:
select min(value) as 'min(value)', max(value) as 'max(value)', sum(value) as 'sum(value)', avg(value) as 'avg(value)' from accounts
Zwróci następujące wyniki:
Wynik działania kodu: select min(value) as 'min(value)’, max(value) as 'max(value)’, sum(value) as 'sum(value)’, avg(value) as 'avg(value)’ from accounts
Dane w bazie bardzo często wymagają aktualizacji. Zmianę wartości można zrealizować poprzez kwerendę update. Ogólna składna wyrażenia jest następująca:
update nazwa_tabeli set kolumna = wartość where warunki_aktualizacji
warunek where jest opcjonalny i można skrócić zapis, jeśli aktualizacja ma dotyczyć wszystkich rekordów w tabeli:
update nazwa_tabeli set kolumna = wartość
Można zmieniać wiele wartości dla każdego rekordu, rozdzielając aktualizowane kolumny przecinkami:
update nazwa_tabeli set kolumna1 = wartość1, kolumna2 = wartość2 where warunki_aktualizacji
Uwaga: Update zakłada lokalną transakcję bazodanową na czas aktualizacji danych.
Przykłady:
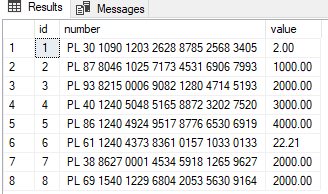
Dla tabeli accounts:
Zawartość tabeli accounts
Zmiana jednej wartości:
Dla id = 1 możemy zmienić zmienić wartość pola value kodem:
update accounts set value = 2 where id = 1
Wartość rekordu z id = 1 została zaktualizowana na:
Wynik działania: update accounts set value = 2 where id = 1
Inne rekordy nie zostały zaktualizowanie, ponieważ w warunku where aktualizacja miała dotyczyć tylko rekordu z id = 1
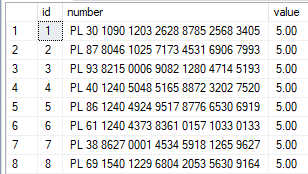
Zmiana wielu wartości:
Możemy zmienić wiele wartości w jednym rekordzie kodem:
update accounts set value = 4, number = 'TEST 12345' where id = 1
W wyniku czego rekord o id równym 1 będzie miał wartość:
Wynik działania: update accounts set value = 4, number = 'TEST 12345′ where id = 1
Aktualizacja całej zawartości tabeli:
Kod:
update accounts set value = 4 where id between 2 and 4
Zaktualizuje value na 4 w tabeli accounts, gdzie id rekordów jest między 2 oraz 4:
Rezultat zapytania: update accounts set value = 4 where id between 2 and 4
Wykonując poniższy kod:
update accounts set value = 5
Zmieni wartości value dla wszystkich rekordów w tabeli:
Wynik kwerendy: update accounts set value = 5
Przepisywanie pul w tabeli:
Poniższym kodem możemy przepisać id do pola value dla każdego rekordu:
Kolejność danych ma znaczenie. Możemy wpłynąć na kolejność zwracanych danych, poprzez wskazanie kolumn po słowach kluczowych order by w zapytaniu select.
Sortowanie rosnące można zrealizować poprzez:
select nazwy_kolumn_do_wyświetlenia from tabela order by nazwy_kolumn
lub inny, równoważny zapis:
select nazwy_kolumn_do_wyświetlenia from tabela order by nazwy_kolumn asc
oraz gdy potrzebujemy posortować dane malejąco
select nazwy_kolumn_do_wyświetlenia from tabela order by nazwy_kolumn desc
Uwaga: Wartość asc jest domyślnym sposobem sortowania i może zostać pominięta.
Uwaga: Dopuszczalne jest użycie numerów kolumn zwracanych w części order by zamiast nazw.
Jeśli niezbędne jest sortowanie po wielu kolumnach, wystarczy wypisać je w odpowiedniej kolejności po przecinku oraz określić, czy kolumny mają być sortowane rosnąco czy malejąco używając operatorów asc oraz desc.
Przykłady:
Order by asc:
Dla danych w tabeli names:
Zawartość tabeli names
Kwerenda sortująca nazwy rosnąco:
select * from names order by name asc
Zwróci wartości:
Przykład: select * from names order by name asc
Taki sam rezultat można uzyskać poprzez jedną z poniższych komend:
select id, name from names order by 2 asc
select * from names order by 2 asc
Order by desc:
select * from names order by name desc
Dla powyższego skryptu otrzymamy wyniki:
Przykład: select * from names order by name desc
Powyższy skrypt jest równoważny:
select id, name from names order by name desc
lub
select * from names order by 2 desc
Sortowanie po wielu kolumnach:
Do tabeli names dodajmy nowy wpis Maria:
Dane do przykładu
Sortowanie po dwóch kolumnach:
select * from names order by name desc, id desc
Zwróci wartości sortowane malejąco po name oraz malejąco po id :
Rezultaty widać na pozycjach id 11 oraz 12 dla takiego samego imienia Maria.
Oraz sortowanie malejąco po name oraz rosnąco po id:
select * from names order by name desc, id
Także rezultat widać po z imieniem Maria dla rekordów z id 11 oraz 12.